I wanted to write this article for a long time, there have been many excellent articles explaining the transformer architecture in detail like Annotated Transfomer . The article covers in detail about every building block of transformers. I would like to extend the article to explain how the matrix operations happen during the training as well as inference.
Transformer architecture is faster compared to LSTM is because of parallel batched multiplications which happen behind the scenes. It's hard to understand this process because it happens in a multi-dimensional space. In the below explanation I would simplify it by splitting the operations in a two dimensional space which are easier to understand.
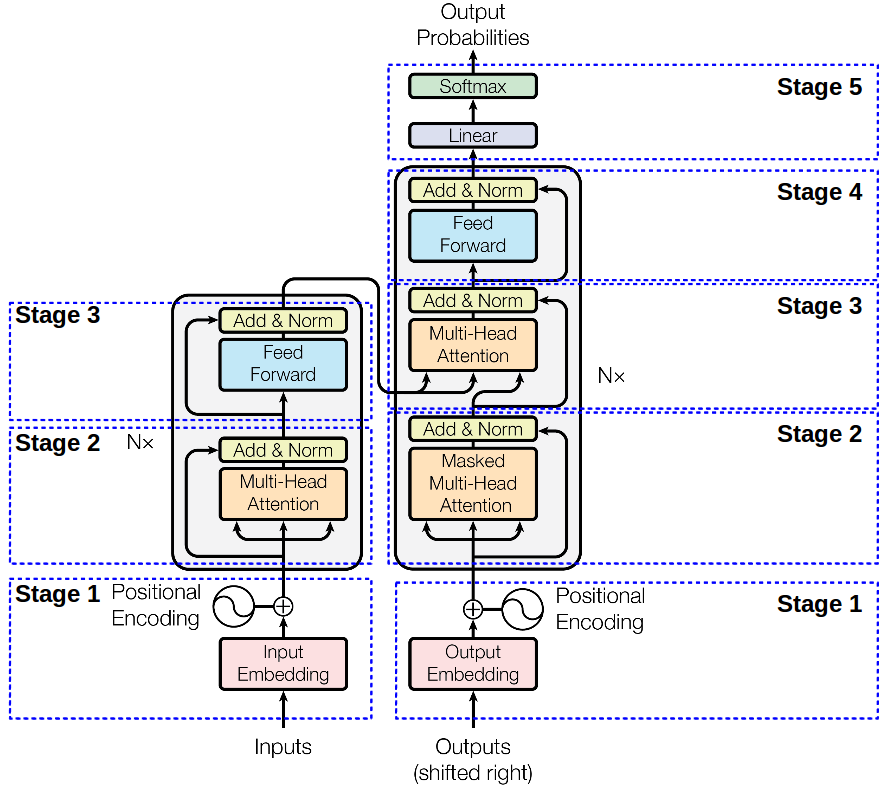
Training of transfomer happens in parallel (all words are passed one shot unlike the autoregressive way in LSTM). Inference in transformer happens in a auto regressive way.(give sos token predict first word then next word ..so on)
To understand the mathematical operations in transformer lets take an example of grammatical error correction.
source sentence : I going to school today.
target setnece : I am going to school today.
Lets assume the basic trainsfomer architecture which has 6 blocks, 8 attention heads and 512 dimesnion of hidden state.As all the 6 blocks have similar operations below is the explanation for one block.
Once we have parallel data (source & target sentence) as mentioned above.
Lets take the batch size for training is 4 , and vocab size is 30k
tokens = [4 x 10] -- batch size x sequence length(no of words)
one hot encoded tokens = b[4 x 10 x 30k]
Word embedding layer is a matrix which projects the one hot encoded tokens into a hidden dimension of length 512.
Wt = [30k x 512]
word embedding = (one hot encoded tokens) * (Wt) -- [4 x 10 x 512]
Postional embedding is a vector of length 512 which uniquly represents an index in the sequence of tokens .
Better explanation here
positional embedding = [4 x 10 x 512]
input to encoder = word embedding + positional embedding -- [4 x 10 x 512] (matrix addition)
Similar calcualtion happens at other attention heads as well.
Output of block 1 of encoder = concatenation of ouput from 8 heads = [4 x 10 x 512](concatenation of 8 matrices on the last dimension)